Terraform vs. AWS CDK: Battle of the IaC Titans
Slides, recording and follow-up materials for my talk "Terraform vs. AWS CDK: Battle of the IaC Titans" at JavaZone 2025.
Table of contents
Abstract
Picking the right Infrastructure as Code (IaC) tool and using it the right way can be the difference between success or failure when developing modern software. There's no lack of tools that try to solve your infrastructure needs, vendors trying to sell them, or posts on Medium, Reddit and Hacker News offering strong opinions (often without context!) on which and how to use them.
Over the years HashiCorp's Terraform and AWS Cloud Development Kit (CDK) have established themselves as key players in the IaC ecosystem, but what are the key differences between them? What are their strengths and weaknesses, and when should you consider using one over the other? And what does the future hold?
From over five years of production experience with IaC and public cloud, mostly from working on internal developer platforms in AWS, I'll answer these questions as well as share tips and tricks on effective use of these tools. We'll also take a brief look at alternatives such as cdktf and Pulumi, and glance at the future.
Come the next IaC meeting at work, this talk should leave you better prepared!
Recording
Slides

Follow-up materials
Various follow-up materials for the talk.
AWS CDK
Demo code
The demo code, which also serves as a good way to organize your CDK codebase, can be found here: https://github.com/stekern/conference-2025-javazone-aws-cdk-demo.
Getting started
- The Official AWS CDK documentation and the Core Concepts provide solid starting points.
- cdk.dev Slack workspace for community interaction.
- constructs.dev for open-source CDK constructs.
Advanced usage
- CDK Aspects allow you to inspect and modify infrastructure before it is synthesized. Tools like cdk-nag use this to validate against predefined rules, ensuring compliance against different standards.
- The default implementation of CDK Pipelines uses AWS CodePipeline as the engine. There exists a GitHub Actions engine that you might want to check out if CodePipeline isn't doing it for you.
- There are many ways to snapshot test your CDK application. Below is a snippet you can try on an existing cdk.out folder for an example of how such a mechanism can work. You'll end up with a
__snapshots__folder that you can add to version control. During CI you can then regenerate the snapshots and fail if they have changed (e.g., usinggit):
npx --package @stekern/cdk-constructs@v1.0.0-dev.51 \
generate-cdk-snapshots cdk.out __snapshots__
- Keep up with https://github.com/aws/aws-cdk-rfcs to see what's in the works.
Terraform
A tip: Keep it simple for as long as possible. You can avoid third-party tools like Terragrunt for quite some time by organizing your code thoughtfully. By all means use additional tooling if you find yourself rebuilding the same functionality, but ensure the benefits outweigh the added complexity.
(Note: I use stack to mean a root module)
One stack per environment
A simple starting point using a parameterized template module instantiated across environments. As complexity grows, consider sub-modules within template (networking, applications, etc.) to create clear boundaries and enable splitting large state files when operations become slow.
terraform/
modules/
template/
dev/
main.tf
staging/
main.tf
prod/
main.tf
Shared and single service stacks
An alternative to the previous approach to start with or grow into is to split the infrastructure into one or more shared stacks containing infrastructure used by multiple applications, and single service stacks containing everything specific to one application - compute instances, application databases, queues, storage. These can evolve at application pace with fewer dependencies.
terraform/
modules/
core/ # shared infrastructure
my-app/ # app-specific infrastructure
my-second-app/ # app-specific infrastructure
dev/
core/
main.tf
my-app/
main.tf
my-second-app/
main.tf
staging/
...
prod/
...
You might also consider moving the application stacks into their respective application codebases to improve cohesion, but ensure they're truly independently deployable first!
A blueprint
Below is a blueprint of an approach I've seen work in practice when a single team owns both infrastructure and application. It cuts through the myriad of decisions you could make by providing a simple framework that's simple and good enough to get started with without locking you into bad choices. Your mileage may vary, but if current approaches are causing friction, these principles might help.
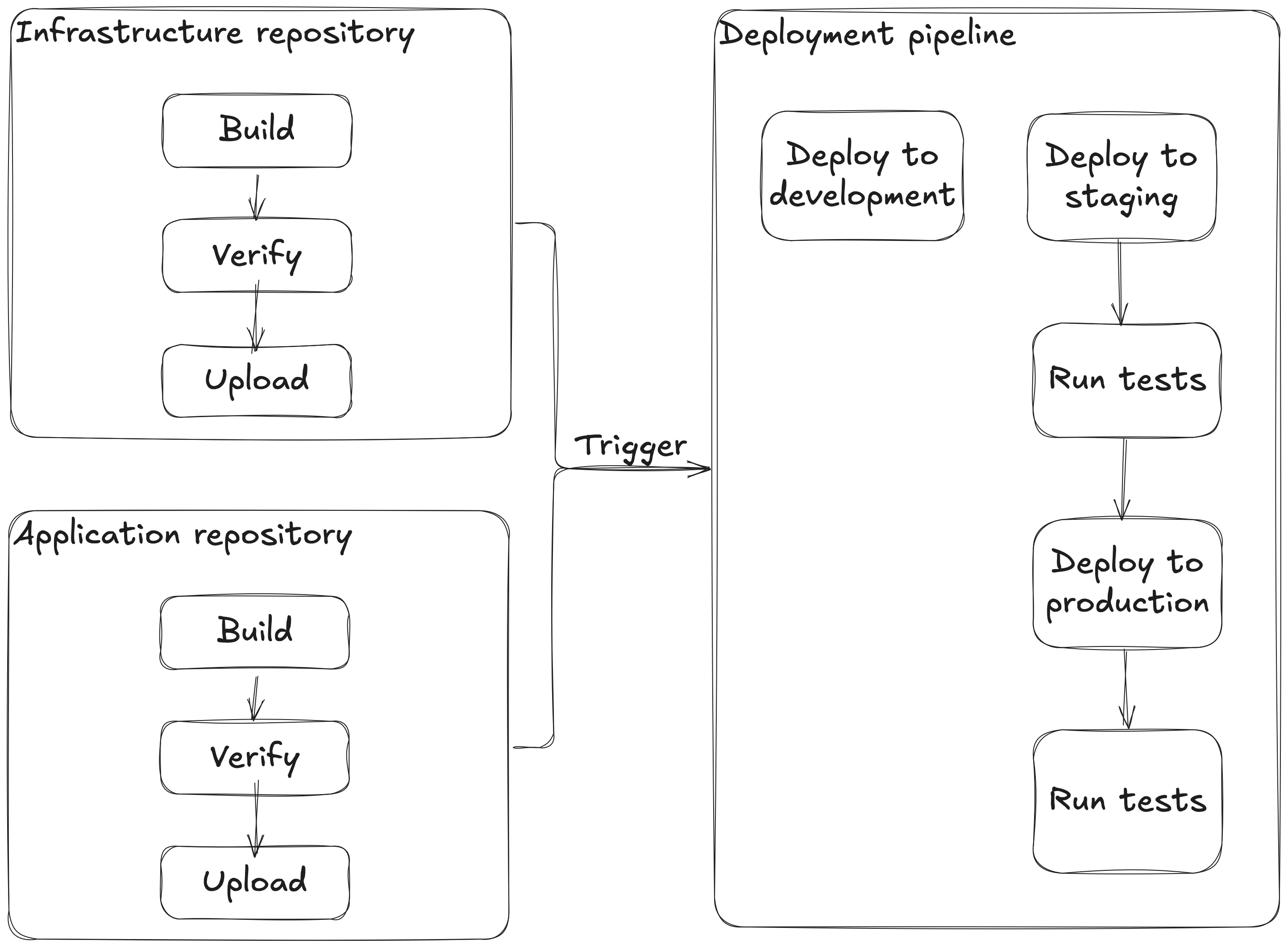
Separate infrastructure from application code
Keeping infrastructure and application code in separate repositories can avoid unnecessary coupling issues by creating clear boundaries. This can work well for more "traditional" applications, however, the more high-level managed services you use (especially serverless), the more tightly coupled your infrastructure and application logic become, making separation less beneficial as they typically change together.
All deployments are infrastructure deployments
By deploying both infrastructure and application changes through the same pipeline using an infrastructure tool (e.g., terraform apply) you get one way of doing things, fewer moving parts, and ensure that infrastructure and application stay synchronized.
When your infrastructure code and application code lives in different repositories, typical mechanisms to connect them during deployment are using AWS SSM parameters to store references to artifacts (e.g., S3 keys, ECR image tags, ...) which are read by your IaC tool of choice during deployment, or store it in a dynamically genereated JSON file that is read during deployment, etc.
Minimum set of isolated environments
Any larger system will likely need at least three environments: development (experimentalenvironment for developers), staging (production-like validation), and production itself. Each serves a distinct purpose in your development process and deployment pipeline.
You might also want to consider introduced a dedicated service account to house artifact repositories and deployment pipelines when using multiple environments. This separates deployment concerns from your application workload accounts.
Parameterized environments
If environments are instances of the same parameterized infrastructure code instead of being independently defined, it is much easier to keep them similar. If staging and production drift too far apart, Continuous Deployment fails because you can't trust staging validation to predict production behavior.
Two-tier infrastructure
By organizing infrastructure into shared stacks (infrastructure that is shared across multiple applications, like networking, load balancing, etc.) and single service stacks (application-specific resources like compute, storage, etc.) you get some separation of concerns with very little overhead. The more you fragment and isolate, the more overhead and orchestration complexity you introduce.
Note that this way of organizing your infrastructure makes it very easy to move app-specific infrastructure into the application codebase later if needed!
Continuous Deployment
Every commit to trunk deploys to production unless a pipeline step fails. There's heaps of things to say about Continuous Deployment and its positive effects, but suffice to say that it uncovers and makes apparent various issues and forces you to fix (or at least acknowledge) them instead of working around them. Teams must, however, own their deployments - when a deployment fails, they fix it.